
Hi! I am currently working as a algorithm researcher in the Autonomous Driving Division of X Research Department, JD Logistics, mainly engaged in the research and development of vision and point cloud perception algorithms.
I obtained my master’s degree from the School of Computer Science and Engineering, Northeastern University, Shenyang, China in 2023, advised by Professor Lu Wang (王璐). I also participated in Tsinghua University’s joint training of graduate students, with Professor Xinyu Zhang (张新钰) and Academician of Chinese Academy of Engineering (CAE) Jun Li (李骏) as my supervisor. During the joint training period, I was responsible for the algorithm research of the perception group, as well as the integration and debugging of each module system of the unmanned vehicle in the Meng Shi Team (清华猛狮团队). Our team achieved significant accolades, including the gold medal in the 2021 World Intelligent Driving Challenge Extreme, first prize in the 2019 i-VISTA Automatic Driving Challenge Competition, and top honors in the City Traffic Scene Challenge Competition.
My research interests lie in the application of deep learning to various computer vision tasks, with a focus on:
- Autonomous driving perception algorithm.
- Multimodal Information Fusion.
- Zero/Few-shot Learning.
🔥 News
- 2024.08 (Pinned): 🔥🔥🔥 I’m excited to announce the release of a new repository on GitHub focused on various attention mechanisms! This repo is designed to make it easier to experiment with and integrate different attention modules, offering a plug-and-play approach to boost performance across tasks. Check it out and feel free to get involved: Attention-Mechanisms
- 2025.01: 🎉 One paper is accepted by IEEE Transactions on Intelligent Transportation Systems (中科院一区Top, IF=7.9).
- 2024.10: 🎉 One paper is accepted by IEEE Transactions on Geoscience and Remote Sensing (中科院一区Top, IF=7.5).
- 2024.07: 🎉 One paper is accepted by Automotive Innovation (中科院一区, IF= 4.8).
- 2024.05: 🎉 One paper is accepted by The 62nd Annual Meeting of the Association for Computational Linguistics (ACL 2024) (CCF A).
- 2024.02: 🎉 One paper is accepted by IEEE Transactions on Intelligent Vehicles (中科院一区Top, IF=14).
- 2024.01: 🎉 One paper is accepted by Engineering Applications of Artificial Intelligence (中科院一区Top, IF=7.5).
- 2023.06: 🎉 Three papers are accepted by IEEE Transactions on Intelligent Vehicles (中科院一区Top, IF=14).
- 2023.05: 🎉 One paper is accepted by IEEE Transactions on Computational Social Systems (中科院二区, IF=5.1).
- 2023.03: 🎉 One paper is accepted by APPLIED INTELLIGENCE (中科院二区, IF=5).
- 2022.08: 🎉 One paper is accepted by IEEE Transactions on Vehicular Technology (中科院二区Top, IF=6.1).
- 2021.08: 🎉 One paper is accepted by ICARM 2021 Best Paper.
📝 Publications
Note: *, #, and bold text indicate equal contribution, corresponding author, and myself, respectively.
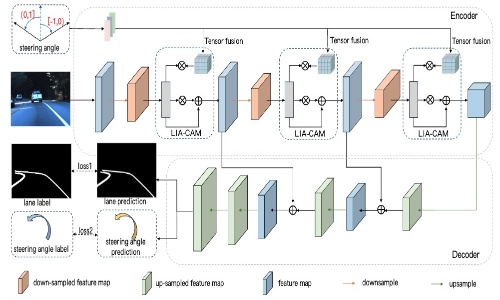
Steering Angle-Guided Multimodal Fusion Lane Detection for Autonomous Driving
Yan Gong, Xinyu Zhang#, Jianli Lu, Xinmin Jiang, Zichen Wang, Hao Liu, Zhiwei Li, Li Wang, Qingshan Yang, Xingang Wu
published on IEEE Transactions on Intelligent Transportation Systems
- We are the first work to introduce steering angle in-formation into lane detection, which adopts LIA-CAM to fuse steering angle features with image features, allowing the network to exploit the implicit relationship between the two to assist lane detection in adverse lighting environments.
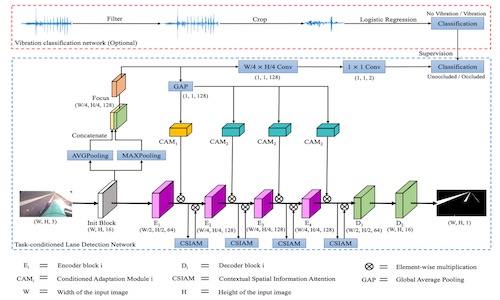
TCLaneNet: Task-Conditioned Lane Detection Network Driven by Vibration Information
Yan Gong, Xinmin Jiang, Lu Wang#, Lisheng Xu, Jianli Lu, Hao Liu, Lei Lin, Xinyu Zhang
published on IEEE Transactions on Intelligent Vehicles
- To deal with occlusion and low-light conditions in the lane detection, we first propose to utilize the vibration signals generated when vehicles pass over the vibration marking lines as supervision for lane occlusion prediction, whose features are then used to adaptively adjust the weights of lane detection network to improve its performance.
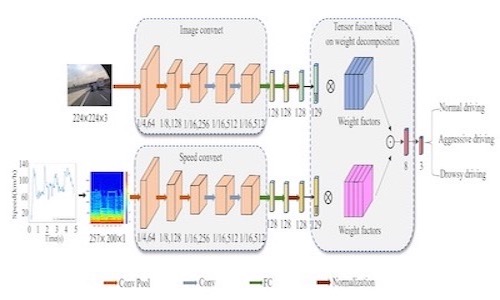
SIFDriveNet: Speed and Image Fusion for Driving Behavior Classification Network
Yan Gong*, Jianli Lu*; Wenzhuo Liu*; Zhiwei Li#; Xinmin Jiang; Xin Gao; Xingang Wu
published on IEEE Transactions on Computational Social Systems
- We first introduce a 2D image with detailed roadside information and convert speeds into a 2D spectrogram using short-time Fourier transform (STFT) to represent their time-frequency characteristics, unifying the data space of image and speed information.
- A tensor fusion method based on weight decomposition is proposed to fully fuse the vectors of the two modalities, achieving leading performance on UAH-DriveSet and distracted driving multimodal dataset.
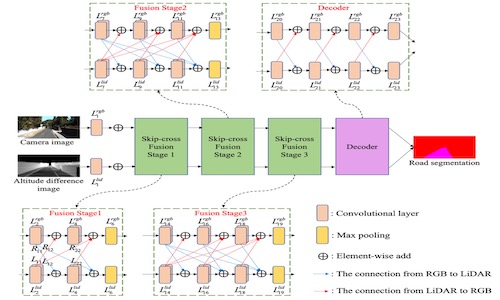
SkipcrossNets: Adaptive Skip-cross Fusion for Road Detection
Yan Gong, Xinyu Zhang#, Hao Liu, Xinming Jiang, Zhiwei Li, Xin Gao, Lei Lin, Dafeng Jin, Jun Li, Huaping Liu
published on Automotive Innovation
- To address the challenges of pedestrian detection under insufficient nighttime illumination, we propose a Feature Aggregation Module (FAM) that adaptively captures cross-channel and cross-dimensional information interactions between two modes.
- The proposed FAM module is embedded into a dual-stream network adapted from YOLOv5. The advantages of FANet are its small size (15 MB) and fast processing speed (8 ms per frame).
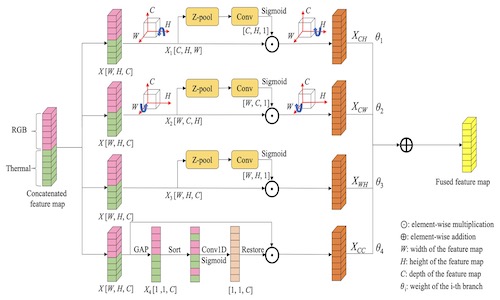
A Feature Aggregation Network for Multispectral Pedestrian Detection
Yan Gong, Lu Wang#, Lisheng Xu
published on Applied Intelligence
- To address the challenges of pedestrian detection under insufficient nighttime illumination, we propose a Feature Aggregation Module (FAM) that adaptively captures cross-channel and cross-dimensional information interactions between two modes.
- The proposed FAM module is embedded into a dual-stream network adapted from YOLOv5. The advantages of FANet are its small size (15 MB) and fast processing speed (8 ms per frame).
Multi-Modal Fusion Technology Based on Vehicle Information: A Survey
Xinyu Zhang, Yan Gong#, Jianli Lu, Jiayi Wu, Zhiwei Li, Dafeng Jin, Jun Li
published on IEEE Transactions on Intelligent Vehicles
- To address the challenges of pedestrian detection under insufficient nighttime illumination, we propose a Feature Aggregation Module (FAM) that adaptively captures cross-channel and cross-dimensional information interactions between two modes.
- The proposed FAM module is embedded into a dual-stream network adapted from YOLOv5. The advantages of FANet are its small size (15 MB) and fast processing speed (8 ms per frame).
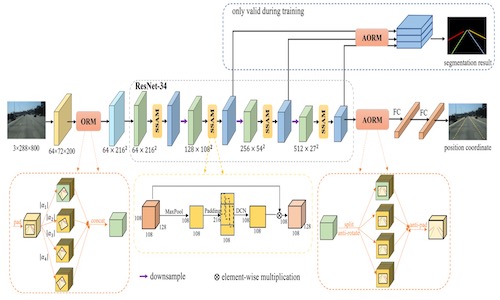
Oblique Convolution: A Novel Convolution Idea for Redefining Lane Detection
Xinyu Zhang, Yan Gong#, Jianli Lu, Zhiwei Li, Shixiang Li, Shu Wang, Wenzhuo Liu, Li Wang, Jun Li
published on IEEE Transactions on Intelligent Vehicles
- To address the challenges of pedestrian detection under insufficient nighttime illumination, we propose a Feature Aggregation Module (FAM) that adaptively captures cross-channel and cross-dimensional information interactions between two modes.
- The proposed FAM module is embedded into a dual-stream network adapted from YOLOv5. The advantages of FANet are its small size (15 MB) and fast processing speed (8 ms per frame).
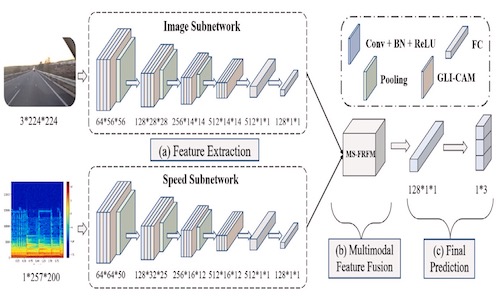
GLMDriveNet: Global–local Multimodal Fusion Driving Behavior Classification Network
Wenzhuo Liu, Yan Gong, Guoying Zhang#, Jianli Lu, Yunlai Zhou, Junbin Liao
published on Engineering Applications of Artificial Intelligence
- We propose a Global-Local Multimodal Fusion Driving Behavior Classification Network (GLMDriveNet), which accurately classifies driver behavior into normal driving, aggressive driving, and fatigued driving, achieving state-of-the-art performance on the public UAH dataset.
- A Global-Local Interaction Channel Attention Module (GLI-CAM) is introduced to extract effective features from roadside images and vehicle speed spectrograms, while a Multi-Scale Feature Representation Fusion Module (MS-FRFM) integrates high-scale and low-scale information, assigning varying importance to different modalities to enhance the network’s focus on useful information.
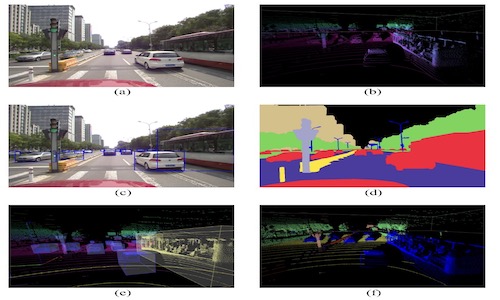
OpenMPD: An Open Multimodal Perception Dataset for Autonomous Driving
Xinyu Zhang*, Zhiwei Li#*, Yan Gong*, Dafeng Jin, Jun Li, Li Wang, Yanzhang Zhu, Huaping Liu
published on IEEE Transactions on Vehicular Technology
- A multimodal perception benchmark for challenging examples is presented for the first time. Compared to existing datasets, OpenMPD places greater emphasis on complex urban scenarios, such as overexposed or dark environments, crowded areas, unstructured roads, and intersections.
- Our data collection vehicle is equipped with 6 cameras and 4 LiDARs, capturing multimodal data with a 360-degree view. We also utilize a 128-beam LiDAR to provide high-resolution point clouds for a better understanding of the 3D environment and sensor fusion. More details can be found on http://www.openmpd.com/.
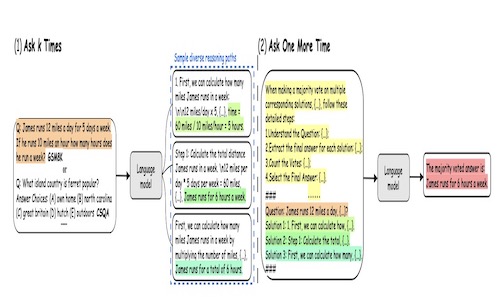
Lei Lin*, Jiayi Fu*, Pengli Liu, Qingyang Li, Yan Gong*, Junchen Wan, Fuzheng Zhang, Zhongyuan Wang, Di Zhang, Kun Gai
published on The 62nd Annual Meeting of the Association for Computational Linguistics
- To address the issues of repetitiveness and local optimality caused by naive greedy decoding in chain-of-thought (CoT) prompting, we propose a general ensemble optimization method. This method is applicable to nearly all types of input problem formats and scenarios where the reasoning path answers may be known or unknown.
- Our method demonstrates outstanding performance and exceptional generalization capabilities across six public reasoning benchmarks.
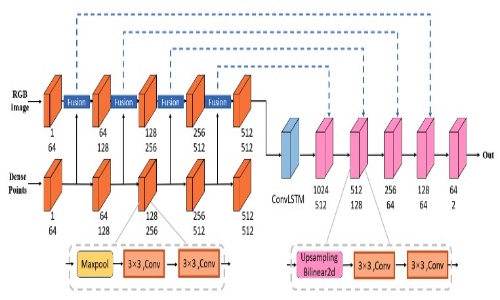
Multi-modal attention guided real-time lane detection
Xinyu Zhang#*, Yan Gong*, Zhiwei Li, Xuan Liu, Shuyue Pan and Jun Li
published on IEEE International Conference on Advanced Robotics and Mechatronics
- We propose an effective real-time model for lane detection, using a fusion strategy to compensate for the limitations of single mode detection and applying multi-frame input to solve the practical problems such as vehicles obstruction and mark degradation.
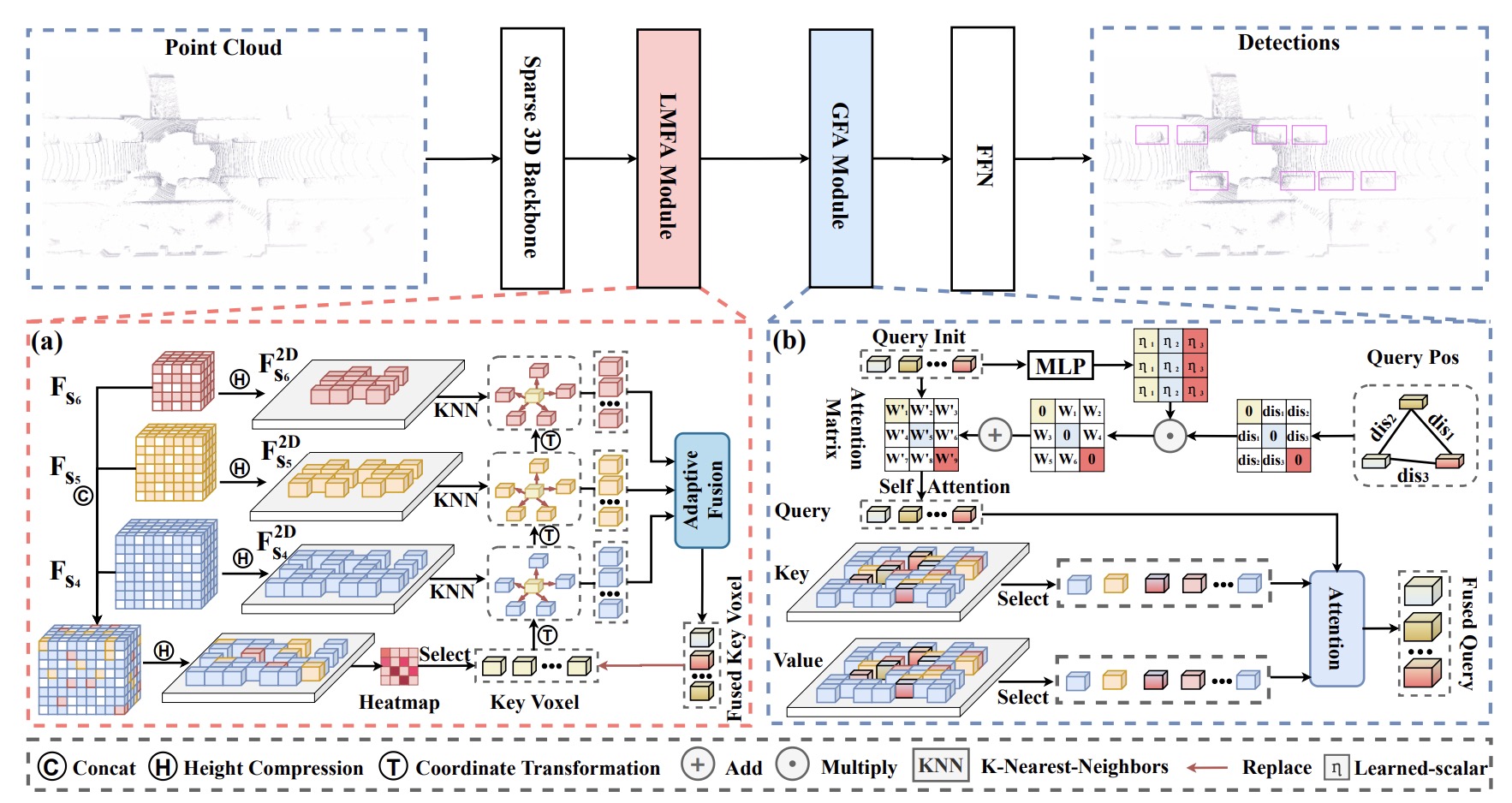
SparseDet: A Simple and Effective Framework for Fully Sparse LiDAR-based 3D Object Detection
Lin Liu, Ziying Song, Qiming Xia, Feiyang Jia, Caiyan Jia, Lei Yang, Yan Gong, Hongyu Pan
published on IEEE Transactions on Geoscience and Remote Sensing
- SparseDet introduces a novel approach to LiDAR-based sparse 3D object detection by using sparse queries as object proxies, enhancing contextual information aggregation through its Local Multi-scale Feature Aggregation (LMFA) and Global Feature Aggregation (GFA) modules.
- Experiments show that SparseDet outperforms the previous best sparse detector, VoxelNeXt, by 2.2% mAP and achieves a faster inference speed of 13.5 FPS on nuScenes, while also surpassing the classical FSDV2 method in both accuracy and speed.
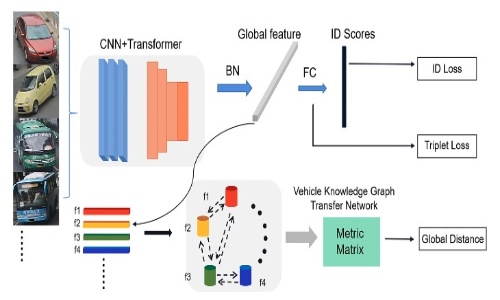
Tvg-reid: Transformer-based vehicle-graph re-identification
Zhiwei Li, Xinyu Zhang#, Chi Tian, Xin Gao, Yan Gong, Jiani Wu, Guoying Zhang, Jun Li, and Huaping Liu
published on IEEE Transactions on Intelligent Vehicles
- We propose a backbone network for vehicle re-identification that leverages CNN and Transformer feature extraction advantages, achieving superior performance by extracting detailed image features, while a vehicle knowledge graph transfer network enhances information correlation across different vehicle types.
📄 Patent
- 一种基于显著性图的多光谱融合行人检测方法及装置, 202310374850.7, 第一发明人,已授权。
- 一种图像和车速信息融合的驾驶行为分类方法及装置, CN115496978A, 第二发明人, 已授权。
- 基于深度学习的劳保用品佩戴情况检测和身份识别的方法, CN111488804A, 第三发明人, 已授权。
- 一种基于振动信号和RGB图像融合的语义分割方法及装置, CN114037834A, 第三发明人, 已授权。
- 基于注意力机制的融合网络车道线检测方法及终端设备, CN111950467A, 第四发明人, 已授权。
🎖 Honors and Awards
- 2024.02, Won the Best Newcomer Award in the Autonomous Driving Department of X Divsion, JDL.
- 2023.10, Won the top 45 in the “Black Horse” Competition in JD.
- 2022.06, Won the top 10 in the 3D semantic segmentation of Waymo dataset.
- 2021.08, Won the “Tomorrow’s Star” honorary title at Tsinghua University.
📖 Educations
- 2020.09 - 2023.06, Joint Master’s Degree, Tsinghua University, Beijing.
- 2020.09 - 2023.06, Master, Northeastern University, Shenyang.
- 2016.09 - 2020.06, Undergraduate, Shanxi University, Taiyuan.
💻 Internships
- 2022.01 - 2022.10, Apollo (Baidu), Autonomous Driving Technology Department, China.
- 2021.11 - 2022.01, Megvii, Development Product Department, China.
- 2021.07 - 2021.11, JD, AI Research Institute, Multimedia and Video Algorithms Department, China.